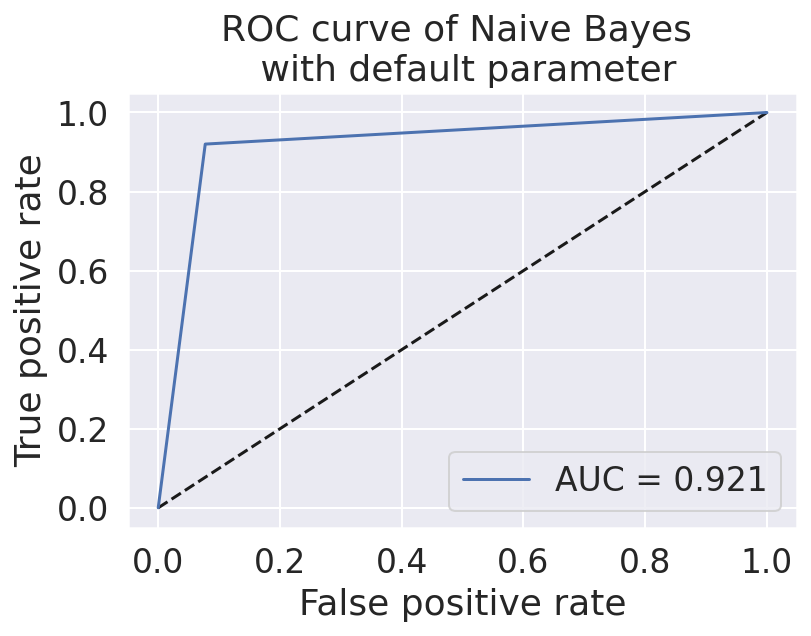
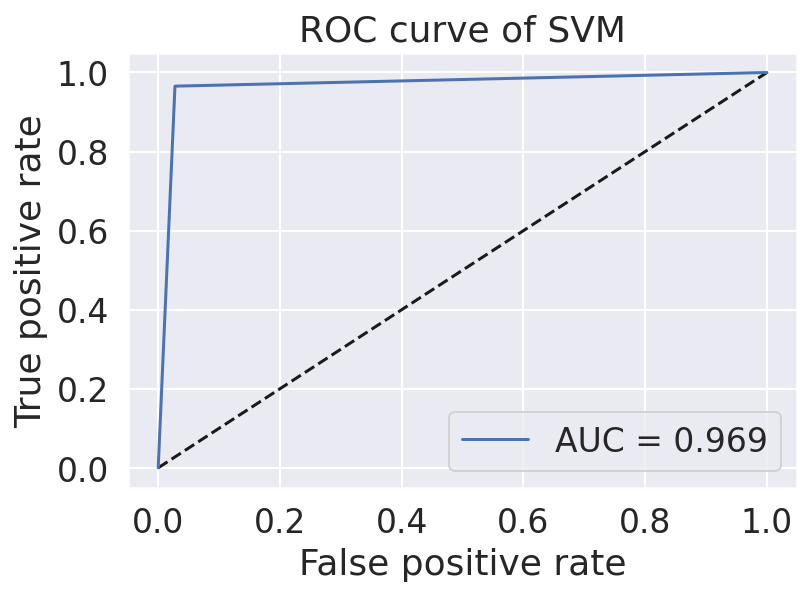
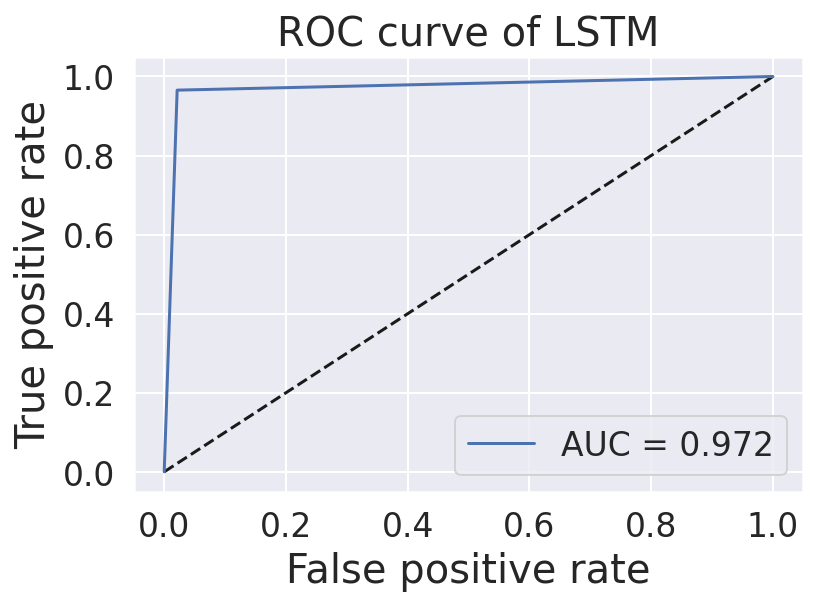
Dataset
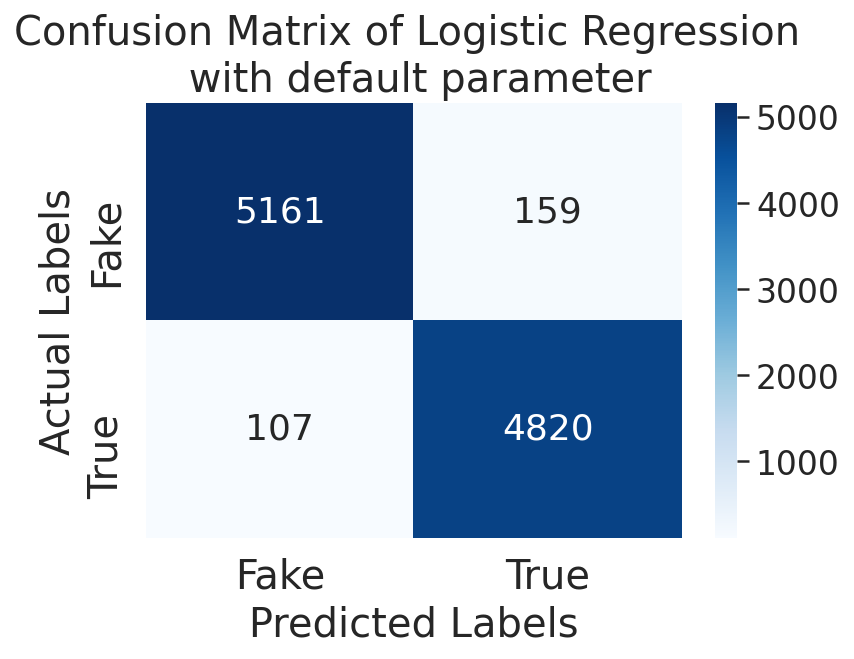
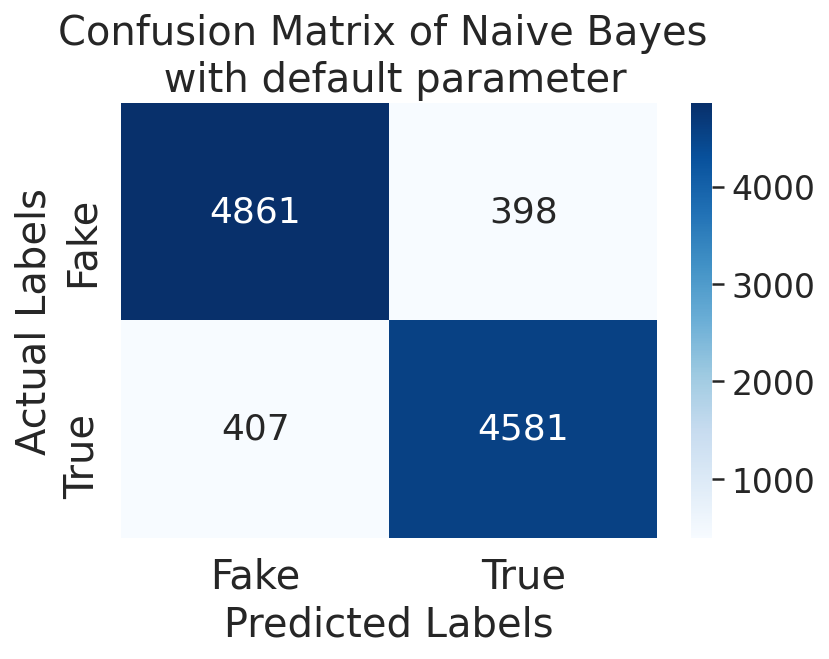
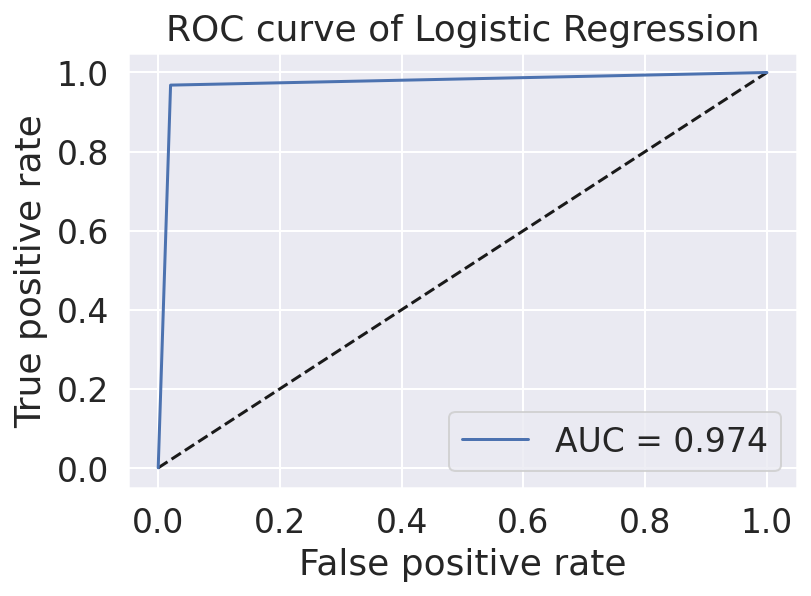
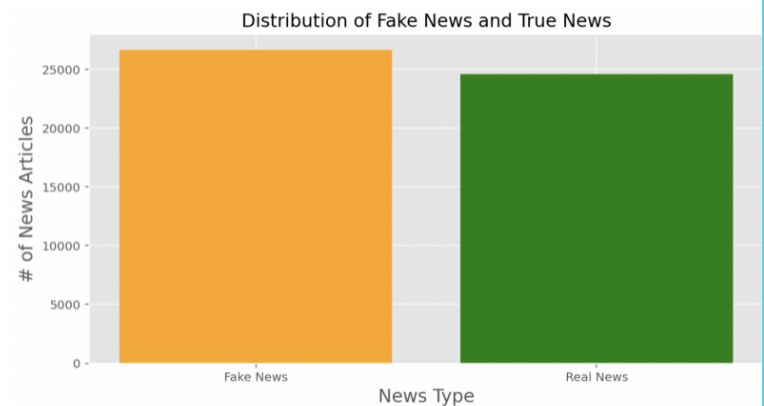
For our product, we collected our data utilizing other datasets from Kaggle. Originally, each dataset comprised of different categories to differentiate each news article, including dates, titles, text, authors, languages, and a real vs. fake classification. Additionally, the dates of each article varied between March 2015 - February 2018. In total, 51,233 news articles were incorporated into our final product, 26,645 of which were fake news, while 24,588 were real news. Furthermore, including both text and titles, a total of 100,575,991 words were used!

"AI Camp introduced new concepts and broadened my horizons through Python exercises and machine learning lectures. Despite the fast-paced curriculum, I was able to pick up an understanding for training models and evaluating their performances along the way. My team communicated frequently and bounced ideas off of each other which was monumental in helping us overcome hitches in the process of designing our website and navigating multiple CoCalc platforms. I was proud to witness the hard work we poured into our final project come to fruition, and am grateful to have had the opportunity to build a foundation for my future projects!"
Audrey Lau
Data scientist, Mathematician

"Overall, I thought my experience at AI Camp was fantastic. At first, I thought the camp was a bit stressful because I was not too knowledgable about Python, in particular. However, the lectures and small group teachings really helped out in learning the fundamentals of both Python and AI. I even enjoyed our final product, the fake news detector, because I believe that it is a key issue which must be addressed. Some downsides of the camp, in my opinion, were that the fast pace can be a bit challenging at times and lectures were sometimes a bit too long. Aside from that, I loved AI Camp and I would recommend it for anyone trying to learn Python and AI."
Ishan Khillan
Mathematician, Web Developer

My experience at AI Camp was very insightful. Through morning lectures, afternoon projects, and Friday game days, I was able to learn about complex topics in AI in a fast-paced environment alongside like-minded individuals. Although we faced some technical difficulties when putting our website together, we were ultimately able to establish a more organized system through communication to ensure that our project could be completed in time. Overall, I'm really grateful to have had the opportunity to be part of AI Camp because I was not only able to expand my knowledge in Python, but I was also able to implement machine learning and AI training models to large-scale products.
Bernice Lau
Data Scientist, Product Manager

"AI Camp is a great way to get into AI and computer science in general. There was plenty of hands-on experience as well as clear and concise lectures. The most challenging part was trying to wrap my head around each of the models and how they worked. However, it was very satisfying to finally fully understand what made each one tick."
Eric Wan
ML Engineer

"I had a very memorable experience at AI Camp. From the start, I was able to understand a lot of the content as I had previously learned Python and other programming languages, so keeping up with the fast pace wasn’t a huge problem for me. Although I did struggle in understanding the applications of the complex Python libraries such as PyTorch, LSTM, etc, but with the repeated explanations by our instructor I was able to figure out it along the way. I benefitted a lot from the individualized attention that was given to us in the camp and I’m pleased with the way our product turned out here at AI Camp! This camp has really helped me set a basis for future AI projects I would like to work on later in high school and through college!"
Datta Kansal
Data Scientist & Product Manager